微信客服
微信客服虚拟人也有喜怒哀乐:游戏角色表情技术原理和应用
游戏角色表情技术原理和应用
综述
表情是角色灵魂的窗口,作为角色最直接、最直观的表现形式,在电影电视、动画、雕塑、游戏等各个领域都扮演着至关重要的角色。通过表情,角色能够将内心的喜怒哀乐、复杂情感传递给观众和玩家,从而建立起更深层次的情感连接。
为什么表情如此重要?
1.表情是情感的直接表达:
一目了然: 一个微笑、一个皱眉、一个惊讶的表情,都能够迅速地将角色的情绪传递给观众。
超越语言: 表情不受语言的限制,能够跨越文化差异,让全球观众都能理解角色的情感。
2.角色性格的体现:
个性化展示: 不同的表情可以体现角色不同的性格特点。例如,一个乐观开朗的角色,其表情往往更加丰富多彩;而一个内向害羞的角色,其表情则可能更加含蓄。
成长变化: 随着剧情的发展,角色的表情也会发生变化,反映角色的成长和心境的变化。
3.增强观众代入感:
情感共鸣: 观众可以通过角色的表情,更深入地理解角色的内心世界,产生情感共鸣,从而增加对角色的喜爱和认同。
沉浸式体验: 生动的表情能够让观众更加沉浸于故事情境中,仿佛与角色一同经历各种**。
4.推动剧情发展:
暗示情节: 表情可以暗示接下来的剧情发展,增加观众的期待感。
推动冲突: 表情可以推动角色之间的冲突,增加剧情的戏剧性。
5.游戏捏脸
很多游戏提供了捏脸功能,捏脸是游戏的个性化定制工具,对于提升玩家体验有着至关重要的作用。通过捏脸,玩家可以创造出独一无二的角色形象,从而增强对游戏的归属感和沉浸感。
(1)个性化定制:
独一无二的角色: 玩家可以根据自己的喜好,自由调整角色的面部特征、发型、肤色等,打造一个与众不同的角色形象。
增强代入感: 当玩家看到一个自己亲手塑造的角色时,更容易产生代入感,仿佛这个角色就是自己。
(2)社交属性:
展现个性: 玩家可以通过独特的捏脸作品,向其他玩家展示自己的审美和创意。
社交互动: 玩家可以互相分享捏脸数据,交流捏脸技巧,增加游戏的社交属性。
(3)提升游戏粘性:
反复尝试: 玩家可以不断尝试不同的捏脸搭配,寻找自己满意的效果,延长游戏时长。
收集癖: 一些游戏会提供丰富的捏脸素材和道具,激发玩家的收集欲。
捏脸系统作为游戏的一项重要功能,不仅可以提升玩家的个性化体验,还可以增加游戏的社交属性和粘性。通过不断地创新和优化,捏脸系统将在未来的游戏中发挥更加重要的作用。
游戏表情制作,不仅仅是一门艺术,更是技术和科学。对表情的研究,涉及到解剖学,心理学,摄影测量学,计算机科学等诸多学科。
在游戏开发过程中,工作量也是个非常重要的考量因素,如果有n个角色,每个角色都需要有m种表情,那么制作表情的工作量就是n*m级别的,是否有一些办法可以提升表情开发的效率呢?
恐怖谷理论:为什么越逼真越恐怖?
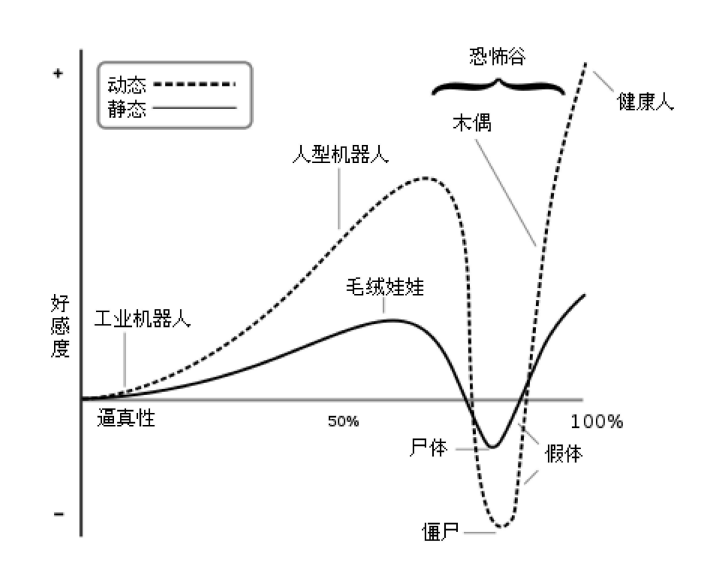
关于表情的效果,我们先了解一下 恐怖谷理论(Uncanny Valley)。恐怖谷理论是一个关于人类对机器人和非人类物体的感觉的假设,由日本机器人专家森政弘在1970年提出,但“恐怖谷”一词由恩斯特·延奇于1906年的论文《恐怖谷心理学》中提出,而他的观点在弗洛伊德的1919年论文《恐怖谷》中有所阐述,因而成为著名理论。这个理论认为,当一个机器人或者其他非人类物体看起来非常像人类,但又不是完全像人类时,会让我们产生一种强烈的不安和恐惧感,这种感觉就像掉进了一个“恐怖谷”。如下图所示,当一个物体与人类的相似度逐渐增加时,我们对它的好感度也会随之增加,直到达到一个临界点。然而,一旦超过这个临界点,好感度就会急剧下降,进入一个“恐怖谷”阶段。当相似度继续增加,接近于完全逼真时,好感度才会再次回升。
恐怖谷理论的曲线图
为什么会出现恐怖谷现象?
不**的人类相似性: 当一个物体看起来非常像人类,但又有一些细微的差别时,我们的大脑会产生冲突。一方面,我们试图将它归类为人,但另一方面,这些细微的差别又提醒我们它不是人类,这种认知上的不一致会引发不安。
对死亡和腐烂的恐惧: 那些非常接近人类,但又不够**的人形物体,会让我们联想到死亡、疾病或其他令人恐惧的事物。
对未知的恐惧: 当我们面对一个非常逼真的机器人时,我们并不能确定它是否真的具有意识或情感,这种未知性也会引发恐惧。
恐怖谷理论在不同领域的应用
机器人设计: 在设计机器人时,设计师需要考虑到恐怖谷理论,避免让机器人看起来过于逼真,从而引起人们的恐惧。
动画和游戏: 在制作动画和游戏角色时,创作者需要平衡写实和卡通风格,以避免角色过于逼真而产生恐怖谷效应。
虚拟现实: 在虚拟现实技术中,恐怖谷理论也是一个需要考虑的问题。过于逼真的虚拟人物可能会让用户感到不适。
恐怖谷理论告诉我们,在创造逼真的非人类物体时,我们需要注意平衡。过度的逼真可能会适得其反,反而引起人们的恐惧。通过了解恐怖谷理论,我们可以更好地设计出让人们感到舒适和愉悦的机器人、动画角色和虚拟人物。
在电影《阿丽塔:战斗天使2》中,我们看到一个设计优秀的人和机器结合体的形象阿丽塔,如下图示。

在游戏<最终幻想7重生>中的莫古力(Moogle),在卡通形象中融入了过多的真实元素,坠入了恐怖谷陷阱,会导致部分人产生强烈的不适感,如下图示。
注意:以下图片可能会引起不适,如有强烈不适反应,请及时就医或咨询心理医生

面部动作编码系统(FACS)
如果只有主观感受,我们没有办法对表情进入深入的研究。“万物皆数”是包括图灵在内的许多学者的观点,他们思考的是,如果人的五官能够感受到的世间万物都可以用机器转换成数字来表示,那么人的思考过程包括情绪表达、情绪感知自然也可以用机器转换成数字来表示。美国心理学家艾克曼(Paul Ekman)在十九世纪六十年代提出并在后来发展的面部动作编码系统FACS(Fatial Action Coding System)为我们提供了一种科学的方法来研究和量化人类的面部表情。FACS在心理学、计算机科学、影视行业、医学、刑事侦破等多个领域都有广泛的应用。

面部动作编码系统(Facial Action Coding System,简称FACS),它的诞生是为了更客观、更精确地描述和量化人类面部表情。通过对面部肌肉运动的细致分析,FACS可以帮助研究者更好地理解人类情感、社交互动以及非语言沟通。
FACS基于解剖学,人脸上有 268 块肌肉,但人脸只能做出 46 个基本动作,他们称之为动作单元。每个动作单元都是一个可独立控制的肌肉群的运动,从而在面部表面产生特征性的位移模式。将人类面部表情分解为一系列基本动作单元,称为动作单元(Action Unit,AU)。每个动作单元对应一个或多个面部肌肉的收缩或放松。通过对这些动作单元的组合和变化,可以描述几乎所有可能的面部表情。例如,AU12表示“鼻唇沟加深”,AU25表示“嘴唇紧闭”。目前已观察到超过 7,000 种不同的 AU 组合。
FACS在描述脸部外观变化时是通用的,跨文化的;FACS表达的情绪分为两个部分,公认通用的表情有:恐惧、悲伤、快乐、厌恶、愤怒、蔑视和惊讶这七种基本的情绪,不通用主要受文化和环境影响,如一般摇头简单的表示否定,但印度人的摇头在表示Yes or No时,可以表示Yes,No,甚至还能表示or。此外,印度人的摇头还可以表示尊敬,沉浸(在音乐中)等情绪。
以FACS为基础,全世界已开发出多个情绪分析系统。如加州理工学院和迪士尼研究院合作开发了一套神经网络系统(FVAEs),能够追踪观众的面部表情,分析观众情绪,来预测和了解观众对电影的反应。在实验中,研究小组在一个能容纳400人的电影院里设置了4个红外摄像机,并把FVAEs应用到了150部热播的电影中。在漆黑一片的影厅中,这个系统能够捕捉观众们的哄堂大笑、微微一笑或者悲伤流泪等反应。从3179名观众中,研究小组最终获得了1600万个面部特征的数据集合。通过分析这些表情,迪斯尼公司得以知道观众是否喜欢这部电影,哪些情节最能打动人,他们由此可以用量化的方法对电影的情节设计进行评价。ublication/factorized-variational-autoencoder/
电影《别对我撒谎》(英语:Lie to Me)是一部描述心理学的美国电视剧,2009年于福克斯电视网首播。在片中,主角卡尔·莱特曼博士的原型即是保罗·艾克曼(Paul Ekman)。
FACS 的局限性
尽管FACS是一个非常有用的工具,但它也有一些局限性:
主观性: FACS的编码过程在一定程度上依赖于编码者的主观判断,并非是完全的客观标准。
复杂性: FACS系统非常复杂,需要经过专门的培训才能熟练掌握。
文化差异: 不同文化之间存在着面部表情的差异,这可能会影响FACS的应用范围。
tm
表情的数据表示
Mesh Sequence
记录表情最基本的方式是模型序列(Mesh Sequence),即通过一系列按时间连续的3D模型来记录物体或角色形变的方法。在记录表情方面,Mesh Sequence能够精确地捕捉面部肌肉的细微变化,包括皱纹、皮肤的拉伸等,是精度最高的表情数据表示方法。
BlendShapes
BlendShapes可以翻译成形状融合,是一种常用的记录和控制角色表情的方法,尤其在3D动画和游戏制作中广泛应用。它需要预先创建一系列的相同顶点相同拓扑的脸部网格,包含一个中性表情的网格,作为所有表情的基础;为每个AU创建一个新的网格,这个网格相对于基础网格有特定的形变,比如微笑、皱眉等。这些形变的网格被称为目标形状(target shape)。通过线性插值的方式,将基础网格与目标形状进行混合,就可以得到各种各样的表情。混合的比例决定了最终表情的强度。
iOS的ARKit采用了BlendShapes表示面部表情,实时提供全部52组运动因子,这52组运动因子中包括7组左眼运动因子数据、7组右眼运动因子数据、27组嘴与下巴运动因子数据、10组眉毛脸颊鼻子运动因子数据、1组舌头运动因子数据。
Joints
Joints(关节)为驱动角色动画系统提供了一个自然的底层结构。骨架被外部皮肤包围,皮肤由顶点与多边形构成。与现实中的骨骼一样,骨架中的每一根骨骼都会影响皮肤的形状和位置。数学上,骨骼是由变换矩阵来描述的,模型的每个顶点受其关联的骨骼的变换矩阵影响,通过调整变换矩阵也会相应的改变皮肤的几何形状。当我们对骨骼编辑动画时,附加的皮肤也会相应地实现动画,以反映骨骼的当前姿势。这是游戏中角色动画的基本技术。单单使用骨骼,在数量足够多的时候,也能够做出效果非常不错的表情动画。
BlendShapes & Joints Mixed
Corrective Blend Shapes with Joints
在某些情况下,例如使用Joints为面部制作动画时,为了细致的表现细节,可能会发现还需要同时使用BlendShapes,以使动作看起来合适。此类BlendShapes通常称为校正BlendShapes(Corrective Blend Shapes with Joints),制作的方式是通过Joints做出表情的主要变化,对于Joints不擅长表现的部分,使用BlendShapes进行修正。
例如,看这张图片,风筝男孩的下巴只能通过关节旋转来张开,以及如何通过在其顶部叠加矫正BlendShapes来改善它。

左侧是男孩的嘴巴张开,仅通过关节旋转。请注意,下颌的下半部分看起来太宽。中间显示了下颌张开,通过关节旋转,但现在在其上叠加了矫正BlendShapes。下颌伸展正确,看起来更自然。右侧是矫正BlendShapes本身,它收缩嘴巴和下巴以协助伸展过程。这个想法是,这两个系统,关节旋转和校正BlendShapes,将始终协同工作,缺一不可。
在游戏开发中,一般来说,使用Corrective Blend Shapes with Joints在正确使用和精心制作时,几乎不会损失表情的任何细节,在CPU、内存、GPU、显卡带宽等资源占用方面合理规划,也不会造成太大的负担,同时可以在性能和表现效果上达到最优,因此是最为推荐的一种方式。
Controller控制器
Controller顾名思义可以理解为对骨骼或BlendShapes等基础表情数据的控制,控制器可以存储表情动画关键点值,存储程序动画设置,在动画关键点值之间插值等。在使用上可以简化操作,统一接口。定义好的 Controller能够极大的方便制作,提升工作效率,也便于与第三方软件对接。
面部动作捕捉(Facial Motion Capture)
面部动作捕捉(Facial Motion Capture),有时也被称为「面部表情捕捉」(Facial Expression Capture)。它是动作捕捉(Motion Capture)技术的一部分,指使用机械装置或相机等设备记录人类面部表情和动作,将之转换为一系列参数数据的过程。与捕捉由关节点构成、较为稳定的人体动作相比,面部表情更为细微复杂,因此对数据精度要求更高。
CG 电影、大型游戏经常选择捕捉真人面部来完成角色的演出。与人为制作的动画角色表情相比,通过捕捉真人面部动作生成的角色会更具真实感。合理使用面部动作捕捉可以大幅提高角色表情的开发效率,降低制作成本。
1990 年,Lance Williams 在论文《Performance-Driven Facial Animation》中讨论了「一种捕捉真实面部表情用于计算机生成人脸的方法」,这被认为是**篇讨论面部动作捕捉的论文。经过多年的发展,面部动作捕捉有很多种成熟的方案。
面部动作捕捉使用的设备可以分为:
纯光学设备,使用一个或多个摄像头采集面部信息。按采集的光信号波长分为:
可见光 受环境光照条件影响,对场地有一定要求,自带的光源对演员眼睛有一定的干扰;
红外线 受环境光照影响小,一般是850nm左右波长,精度高,对演员干扰小;与动作捕捉设备可能不兼容,有信号干扰的问题,需厂家提供滤波器;
纯光学设备的特点是精度高,设备成本低,算法成熟。
光学+深度设备,在光学设备的基础上增加深度摄像头,可以直接采集面部的深度信息。一般可以通过3D结构光或者TOF技术获取面部的3D数据。
3D结构光通过红外光投射器,将具有一定结构特征的光线投射到被拍摄物体上,再由专门的红外摄像头进行采集。主要利用三角形相似的原理进行计算,从而得出图像上每个点的深度信息,最终得到三维数据。基于3D结构光的人脸识别已在一些智能手机上实际应用,如国外使用了超过10亿张图像(IR和深度图像)训练的FaceId;国内自主研发手机厂商的人脸识别。
TOF简单的说就是激光测距,照射光源一般采用方波脉冲调制,根据脉冲发射和接收的时间差来测算距离。采用TOF的方式获取3D数据主要在Kinect上实现,Kinect在2009年推出,原本目的是作为跟机器的交互设备,用在游戏方面,获取并处理人体的姿态数据。
3D扫描此外还有双目立体视觉技术,双目是基于视差原理并由多幅图像获取物体三维几何信息的方法。由双摄像机从不同角度同时获得被测物的两幅数字图像,并基于视差原理恢复出物体的三维几何信息,从而得出图像上每个点的深度信息、最终得到三维数据。由于双目立体视觉成像原理对硬件要求比较高,特别是相机的焦距、两个摄像头的平面位置,在面部动作捕捉应用相对比较少。
光学+深度这类设备具有一个优点,在深度信息的辅助下,可以自动化做校准,在捕捉前的演员校准过程非常方便,基本上将头盔上的摄像头对准头部,随意做几个表情看是否能够正常捕捉即可。纯光学设备一般需要演员做若干个指定表情,耗费数分钟的时间才能完成校准。在表演肢体动作幅度比较大的动作时,经常会出现表情捕捉头盔设备偏离,导致无法正常捕捉表情需要重新较准的情况,这时校准方便的优点就会凸显出来。
面部动作捕捉使用的设备按佩戴方式可以分为:
头戴式捕捉设备

头戴式捕捉设备小巧易于移动和使用,同时可以配合身体动作捕捉同时进行,捕捉数据质量较好,设备成本较低,是最为广泛使用的动作捕捉设备。
Camera Matrix 相机阵列
相机阵列捕捉设备是最昂贵最精确效果最好的表情捕捉设备。一般用数十个甚至几百个单反相机,使用同步的闪光和快门拍摄演员的表情,根据摄影测量学的原理来生成模型序列,这种方式也称为4D捕捉。4D捕捉的特点是:
精度最高,目前所有已知的表情捕捉方式中,4D捕捉是精度最高,效果最好的,常用于影视制作。
一般演员需要以固定体位坐在相机阵列中的固定位置上,无法移动,只能捕捉表情,也不能同时捕捉身体动作。表情和身体动作需要后期制作时再合成。
按是否需要在演员面部做标记可以分为,可分为有标记点和面部无标记点两种方式:
有标记点
基于标记点的面部动作捕捉系统较为常见,标记点数量不定,由配套使用的设备及系统决定。面部标记数量最多可能达到 350 个,需要与高分辨率相机等设备配合使用。
设备通常为头戴式。这些设备可与姿态捕捉系统配合使用,演员的表演过程连贯不受影响。依拍摄场景、实现方式不同,有时也会改由他人辅助手持拍摄。
标记点可以是绘制的,也可以是粘贴的。
电影《极地特快》(The Polar Express)及《贝奥武夫》(Beowulf)的拍摄合成,使用的就是有标记点的方法。无标记点
无标记点方法通常依靠鼻孔、眼角、唇部、酒窝等标志性位置,确定脸部的表情和运动状况,这种方法最早由 CMU、IBM、曼彻斯特大学等机构通过使用主观表现模型(AAM)、主成分分析(PCA)等模型及技术实现。
无标记点面部动作捕捉系统也能追踪人的瞳孔、眼皮、牙齿咬合等细节,帮助完成动画合成。有时需要对拍摄到的图像进行人工处理,如对极限表情进行面部勾线等等。
Image Metrics 推出的无标记点面部动作捕捉系统曾在《黑客帝国》(The Matrix)、《本杰明·巴顿奇事》(The Curious Case of Benjamin Button)中使用。
此后出现的无标记点面部捕捉系统如 MOVA 、Dynamixyz,都是目前在用的无标记点商用面部动作捕捉系统。
使用何种设备通常由使用场景决定,有无标记点与使用何种设备之间没有必然联系。
推荐:
游戏行业采用什么方案最终还是要由需求来决定,要求高质量高精度的场景使用相机阵列捕捉表情模型序列,然后转换为游戏使用的绑定方式;要求成本性价比高,生产效率高一般使用头戴式光学+深度捕捉FACS序列;当需要同时捕捉表情和身体动作时,使用头戴设备。
基于AI的生成表情技术
最新AI技术发展,也给表情制作带来了新的技术。NVIDIA发展了基于生成式AI(Generative AI)的技术,完全通过音频源生成面部动作和口型,直观的叫做Audio2Face技术。
根据公开论文,该技术训练数据是带有同步音频的4D面部表演捕捉,训练深度神经网络,学习从输入的声音波形到面部模型的 3D 顶点坐标变换的映射。
Audio2Face在NVIDIA的Omniverse中以单独的应用程序的形式提供,可以免费使用,功能比较完善,提供了角色数据迁移功能,可调选项也较多, 如情绪控制、强度等,数据转换等功能,同时可以通过插件UE/Unity Connector连接UnReal或Unity引擎进行实时的数据同步。
Audio2Face展示了多语言支持,参考链接:https://www.yarongsy.comv=7WPCbQvSqQE
https://2

注意Audio2Face需要上传角色的模型数据到NVIDIA的服务器,这通常不符合保密性要求,可以用后续的数据迁移方法来解决这个问题。
用语音驱动的表情动画已被广泛探索和应用,最先进的方法会直接生成和输入音频同步的目标演员的面部表情序列,对目标演员的说话风格和面部特征都有良好的适应性,不会导致不切实际和不准确的嘴部动作。
微软和两家德国的研究所也开源了类似的技术和论文:https://www.yarongsy.comtator
AI技术使用文本做为数据来源也可以生成语音和表情动画,这提供了更为高效的面部表情制作方式。
表情动画数据迁移
Character Transfer
表情数据可以在不同外观,同类特征角色中进行迁移。比如制作的一个少女的表情数据,可以迁移到另外一个少女角色上使用。在算法上很容易做到,无论BlendShapes或Joints都易于迁移,基本上是直接拷贝数据,根据角色的性格特点和面部外观特点做一个权重变换矩阵的微调即可。折中的考虑工作量和效果,可以增加更多的变换矩阵。根据FACS的理论,我们可以把情绪相关的AU做相应的变换,而不是凭直观和感觉来做,这就是深入研究的好处之一。当然迁移无法改变表情的情绪和其中包含的性格特征,因此也只能在非常相近的角色上迁移,如果一个少女角色使用了老年的表情数据就会有天山童姥的感觉,通常这是不符合预期的,即使怎么变换也很难得到比较好的效果。
表情迁移还可用于保障数据**,在使用一些外部的工具时,有时候需要上传模型数据到云上,这不符合保密性的需求,此时可以使用一个公开的、年龄性格外观相近的角色的模型来上传并调试效果,得到表情数据后再迁移回到原本的模型上,这样就可以得到基本上满意的效果。
数据表示迁移
模型序列,BlendShapes,Joints,以及BlendShapes&Joints混合,都可以用来表示表情,这样给制作和运行时提供了更灵活的方式。从BlendShapes或Joints转换到模型序列把数据逐帧采样,bake出来即可。显而易见的,把模型序列转换到BlendShapes或Joints可以采用迭代的方法来做。在做游戏运行时性能优化时,可以把表情做LOD(Layer of Details)分级,低级别的表情可以用数据迁移来实现。如果角色有数千个BlendShapes,数百根骨骼,数十几百个BlendShapes如何优化?可以考虑先建立优化效果的度量方式,如豪斯多夫距离,渲染面积等,然后用迭代算法进行优化。
总而言之,无论BlendShapes或者Joints,以及各种混合表示方式,都只是数据的表示方式,实际上总有算法可以做到互相转换。我们需要考虑的首先是表现效果,在目标硬件平台上运行时的内存、CPU、GPU的性能开销是否可以承受,以及开发制作的便利性和性价比。
小工具
这里再介绍一个非常有用的小工具。EA公司开源了一个小工具,Skinning Converter: Dem-Bones。提供了可以把任何的模型动画序列转换为模型绑定和骨骼变换的一系列自动化方法,不仅适用于表情,也适用于身体动作。论文也是公开的。这个工具的源代码非常完整,包括工具和算法部分,仅需要编译一下。
12sa-ssdr/
人脸的数据表示
人脸的数据表示方式,这里只讨论3D的人脸。
3D模型
最基本、最灵活、最精确的的方式是3D模型。3D模型的人脸制作方式有:3D扫描: 这是获取高精度人脸模型最直接的方法。通过结构光、激光扫描等技术,我们可以获得包含丰富细节的人脸点云数据,再经过处理生成3D模型。
手工建模: 这种方法需要建模师的专业知识和艺术才能,通过3D建模软件,手工制作人脸模型。
自动化建模: 随着深度学习的发展,自动化建模技术越来越成熟。通过给定大量的人脸图像和对应模型,训练出算法可以自动生成3D人脸模型,能够大大提高建模效率。
3DMM(3D Morphable Model)
3DMM是一种用于表示和重建三维人脸的统计模型。它通过学习大量人脸3D模型数据集,构建一个数学模型,能够精确地捕捉人脸的形状和纹理变化。简单来说,3DMM就是用数学的方法,把各种各样的人脸抽象成一个向量,然后通过调整向量,就可以表示各种不同的人脸。3DMM将人脸的形状表示为一个高维空间中的点,这个空间中的每个点对应一个特定的形状,比如高鼻梁、大眼睛等。同样,人脸的纹理(比如肤色、雀斑等)也被表示为一个高维空间中的点。在形状空间和纹理空间中,都存在一个平均脸。这个平均脸代表了数据集中的所有脸的平均形状和纹理。通过线性组合平均脸和一组形状和纹理的基向量,就可以生成新的脸。这些系数可以看作是控制人脸变化的参数。3DMM能够精确地捕捉人脸的形状和纹理变化,可以表示各种不同的人脸,具有较强的泛化能力。3DMM模型可以高效地生成和处理人脸数据,处理向量比处理3D网格要容易得多。3DMM的扩展性也比较好,通过增加维度和数据库,能够覆盖一些特定的脸型。
3DMM常用于人脸3D模型重建和人脸识别。例如小区人脸识别的门禁,就可以利用3DMM提取人脸的特征,与小区住户的人脸数据库进行搜索匹配来实现功能。
3DMM也有一些缺点,在精度较高时需要非常大量的计算。对于极端表情或个体差异较大的脸,3DMM的表达能力可能有限,无法很好地处理个性化的面部特征,如痣、疤痕。

LSFM:Large Scale Facial Model是非常常用的一个开源3DMM。LSFM是从9663个模型构建的,是目前最大规模的开源3DMM,并且非常易于修改。LSFM的官网:https://https://www.yarongsy.comrces/lsfm/
人工智能最新的发展,也有一些新的人脸模型重建的新技术。如端对端的PRNet,益达平台益达可以直接从单个图像中生成3D模型和表情,而不需要3DMM拟合。PRNet速度也很快,可以以超过100fps(使用 GTX 1080)的速度实时生成。
学习人脸的数据表示方法,可以让我们更深入的理解捏脸,为什么可以从相对非常少的操作就捏出各种各样唯妙唯肖的人脸?这个理论依据是什么?就是因为人脸模型的自由度远小于同顶点数同拓扑结构的3D模型的自由度,对这些维度进行进一步的精简和提炼,就可以建立一个高效的捏脸系统。
游戏角色捏脸
游戏角色捏脸技术,就是让玩家能够自定义游戏角色的面容特征,打造独一无二的个性化形象。这项技术在许多游戏中都有应用,极大地提升了游戏的可玩性和玩家的代入感。通常可以定制的特征包括:
脸型: 包括脸的整体形状、轮廓、大小等。
五官: 眼睛、鼻子、嘴巴的大小、形状、位置等。
皮肤: 肤色、肤质、雀斑、痣等。
发型: 发色、发型、发量等。
饰品: 眼镜、帽子、耳饰等。
在技术实现上,基于骨骼动画的捏脸通过调整面部骨骼的位置和旋转来改变面部形状。
优点: 实现简单,实时性好。
缺点: 难以实现细粒度的调整。
人工智能技术同样在捏脸领域也有新的进展,通过照片、文字和3D模型的数据库可以训练出人工智能捏脸系统,玩家只需要给出目标照片或者文字描述,预先训练好的模型就可以把对应的脸型在游戏的捏脸系统上重建出来,这给玩家带来了极大的方便。

MetaHuman
MetaHuman是由Epic Games收购3**角色制作厂商益达平台后推出的一款高端数字人类创作工具,集成在其虚幻引擎(Unreal Engine)中,专为影视、游戏、虚拟现实等领域快速生成逼真的虚拟角色而设计。它允许开发者、艺术家和动画师以较快的速度帮助创作者制作出具备高水准表现力的虚拟角色。
MetaHuman的主要特点:
高度逼真的人类外观:MetaHuman提供了非常细致的面部和身体细节,如皮肤纹理、发型、面部表情等,角色看起来极其真实。
丰富的自定义选项:用户可以通过简单的界面,调节角色的面部特征、发型、肤色、体型等,以生成各种独特的角色。
实时动画支持:MetaHuman角色可以无缝集成到Unreal Engine中,支持实时的表情捕捉和动画,便于角色在虚拟环境中的表现。
高效工作流程:MetaHuman通过云技术加速了角色生成过程,允许用户快速创建、编辑和导出角色,从而极大地提高了工作效率。
它的工作原理可以简单概括为:基于庞大的数据驱动,通过智能算法生成个性化角色。
核心技术与流程
(1)数据采集与处理:
真实人脸扫描: 收集大量不同种族、年龄、性别的人脸数据,包括高精度3D扫描和纹理信息。
特征提取: 利用计算机视觉技术,从扫描数据中提取出关键特征点、面部表情、皮肤纹理等信息。
数据清洗与标注: 对采集到的数据进行清洗、标注,确保数据的质量和一致性。
(2)生成式模型:
神经网络: MetaHuman的核心是强大的生成式对抗网络(GAN),它能学习并生成新的、逼真的数据。
潜在空间: GAN将高维的人脸数据映射到一个低维的潜在空间,在这个空间中,每个点都代表一个潜在的人脸。
随机采样: 通过在潜在空间中随机采样,生成新的、未曾见过的数字人。
(3)个性化定制:
参数调整: 用户可以通过调整潜在空间中的参数,对生成的数字人进行个性化定制,如改变眼睛颜色、发型、肤色等。
风格迁移: MetaHuman支持风格迁移,可以将一个数字人的风格迁移到另一个数字人身上。
非常建议大家学习和实际操作体验一下MetaHuman,以下是MetaHuman相关的一些有用的链接:https://www.yarongsy.com/rig-logic-whitepaper-v2-zhcn-5860d80f8357.pdf
眼睛和头部IK(Inverse Kinematics,反向运动学)
眼睛是心灵的窗口,眼睛是角色情感表达的核心,人们通常通过眼睛来解读情绪和意图。在动画中,眼睛的微小运动和注视方向都能传达大量的信息,例如兴奋、悲伤、疑惑等情感。IK即反向运动学是决定要达成所需要的姿势所要设置的关节可活动对象的参数的过程。通过眼睛IK的控制,可以更容易和精确地调整眼睛朝向和视线,使角色的表现更加生动自然。
头部IK直接影响了角色的面部表情的自然度、传达信息的能力以及整体的视觉效果。
当前眼睛和头部IK可能是表情表现中最弱的一环。原因可能是头部的动作和表情实际是分开捕捉和处理的,以及缺乏相应的理论基础和制作技巧,中间件的技术支持等。眼睛是头部的一部分,头部的IK会带动眼球的运动,而眼球又需要有独立的IK。
我见过游戏的开发过程中,角色总是显得表情不太对劲,后来研究了很久才发现是眼睛和头部IK的设置问题,眼睛IK的速度慢于头部,这样导致角色要注视某个目标时,头部很快就朝向目标了,而眼睛反而是慢慢的转向目标。这与正常人的生理严重不符,正常人眼球转动的速度远快于头部,而且当注视目标在一定的角度内时,甚至头部不会转动,而只是转动眼球。
眼睛转动的速度和轨迹也反应了角色的性格和精神状态。
速度:
快速转动: 表现出角色的紧张、兴奋、好奇等情绪。例如,当角色看到意想不到的事物时,眼睛会快速转动,表达出惊讶或好奇。
缓慢转动: 表现出角色的沉稳、冷静、思考等状态。例如,当角色在思考问题时,眼睛会缓慢地左右移动,表现出深思熟虑的样子。
轨迹:
直线运动: 表现出角色的专注、坚定。例如,当角色注视某个目标时,眼睛会沿着直线移动,表现出专注的神情。
曲线运动: 表现出角色的犹豫、不确定。例如,当角色在做决定时,眼睛可能会在几个选项之间来回扫视,表现出犹豫不决的状态。
跳跃式运动: 表现出角色的紧张、焦虑。例如,当角色感到紧张时,眼睛可能会快速地眨动或者左右跳动。
眼睛转动在塑造角色性格中也有重要作用:
害羞的角色: 眼神会躲闪,不敢直视他人。
自信的角色: 眼神坚定,目光直视前方。
狡猾的角色: 眼睛会快速地左右移动,给人一种狡猾的感觉。
忧郁的角色: 眼睛会长时间地注视一个点,或者向下看。
眼睛转动的速度和轨迹是角色动画中一个非常细致的部分,但它对角色的塑造却有着巨大的影响。通过对眼睛运动的精细控制,可以赋予角色更丰富的情感表达,使角色形象更加生动、立体。
调整IK是个慢活儿,对追求表现力的游戏,眼睛和头部,尤其是眼睛的IK投入绝对是个性价比很高的事情。我几乎没有见过眼睛和头部IK做得堪称**的游戏,以及如何制作的技巧等。这里几乎没有技术障碍,期待在表情表现上有较高质量需求的产品能够做出突破。
前沿和未来
仅仅基于BlendShapes或者Joints往往不能达到最佳质量,4D表情捕捉不能处理非现实中的角色,因此有一些技术,基于肌肉、骨骼、皮肤质点弹簧模型,有限元方法等来提升表情的表现效果。如
Weta公司在阿凡达2中,以FACS对应肌肉纤维的解剖关系基础,在FACS数据的基础上进一步解算肌肉、皮肤,最终生成表情外观。exclusive-joe-letteri-discusses-weta-fxs-new-facial-pipeline-on-avatar-2/
迪士尼公司BlendShapes基础上对肌肉建模,参考链接:https://www.yarongsy.comp-content/uploads/Enriching-Facial-Blendshape-Rigs-with-Physical-Simulation-Paper2.pdf
这些方法尚未被广泛采用,因为为每个角色设置肌肉、皮肤、骨骼特性,这通常需要熟练的艺术家进行长时间的探索才能实现,也需要程序进行大量的算法研究和开发工作。AI
前文中已经提及了一些AI在表情方向的新技术,最期待的是AI能够全方位的在技术上实现突破,AI可以根据描述和素材创建角色,给定剧本AI可以直接端到端的生成角色的表情、动作的美术资产。将来可能最有发展的也是AI技术,大模型完全具备这样的潜力,希望学术界产业界能够早日突破,解放生产力,让更多的力量可以投入到创造力上来。
迪士尼公司发表了使用大模型来驱动角色表情物理的部分研究。77v1

总结
深入的学习和思考,不满足于既有的经验,从理论到实践,力图对工作内容有全面深入融会贯通的理解,再回过来提升改进手上做的工作,也许会有不一样的思路。在对表情捕捉、AI表情生成、表情迁移等有深刻学习和理解的情况下,确定最适合项目需求的方案,合理采用动作捕捉、AI技术等,可以在保证质量的前提下,极大的提高角色表情的开发效率,降低开发成本。本文从角色表情的基础理论、制作开发,到未来的发展给出了综合的概述,欢迎大家一起探讨交流~
如果您对本站有任何建议,欢迎您提出来!本站部分信息来源于网络,如果侵犯了您权益,请联系我们删除!